> ## Documentation Index
> Fetch the complete documentation index at: https://docs.z.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Thinking Mode
> GLM offers multiple thinking modes for different scenarios. The sections below explain how to enable each mode, key considerations, and example usage.
## **Default Thinking Behaviour**
Thinking is activated by default in GLM-5.2 GLM-5.1 GLM-5 GLM-4.7 series, different from the default hybrid thinking in GLM-4.6.
> If you want to disable thinking, use:
```bash theme={null}
"thinking": {
"type": "disabled"
}
```
## **Interleaved thinking**
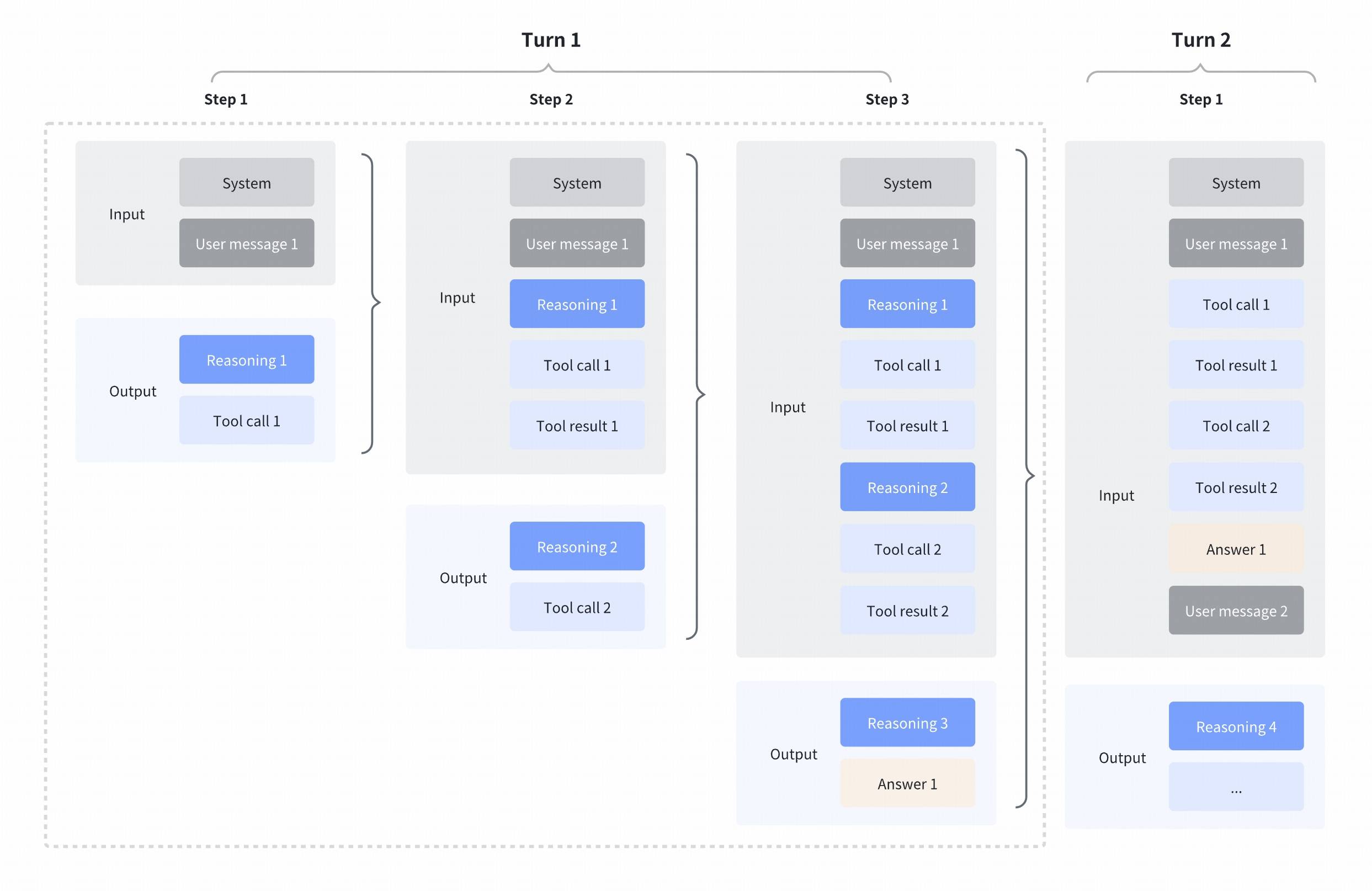
We support **interleaved thinking** by default (supported since GLM-4.5), allowing GLM to think between tool calls and after receiving tool results. This enables more complex, step-by-step reasoning: interpreting each tool output before deciding what to do next, chaining multiple tool calls with reasoning steps, and making finer-grained decisions based on intermediate results.
When using interleaved thinking with tools, **thinking blocks should be explicitly preserved and returned together with the tool results.**
The detailed interleaved thinking process is as follows.
## **Preserved thinking**
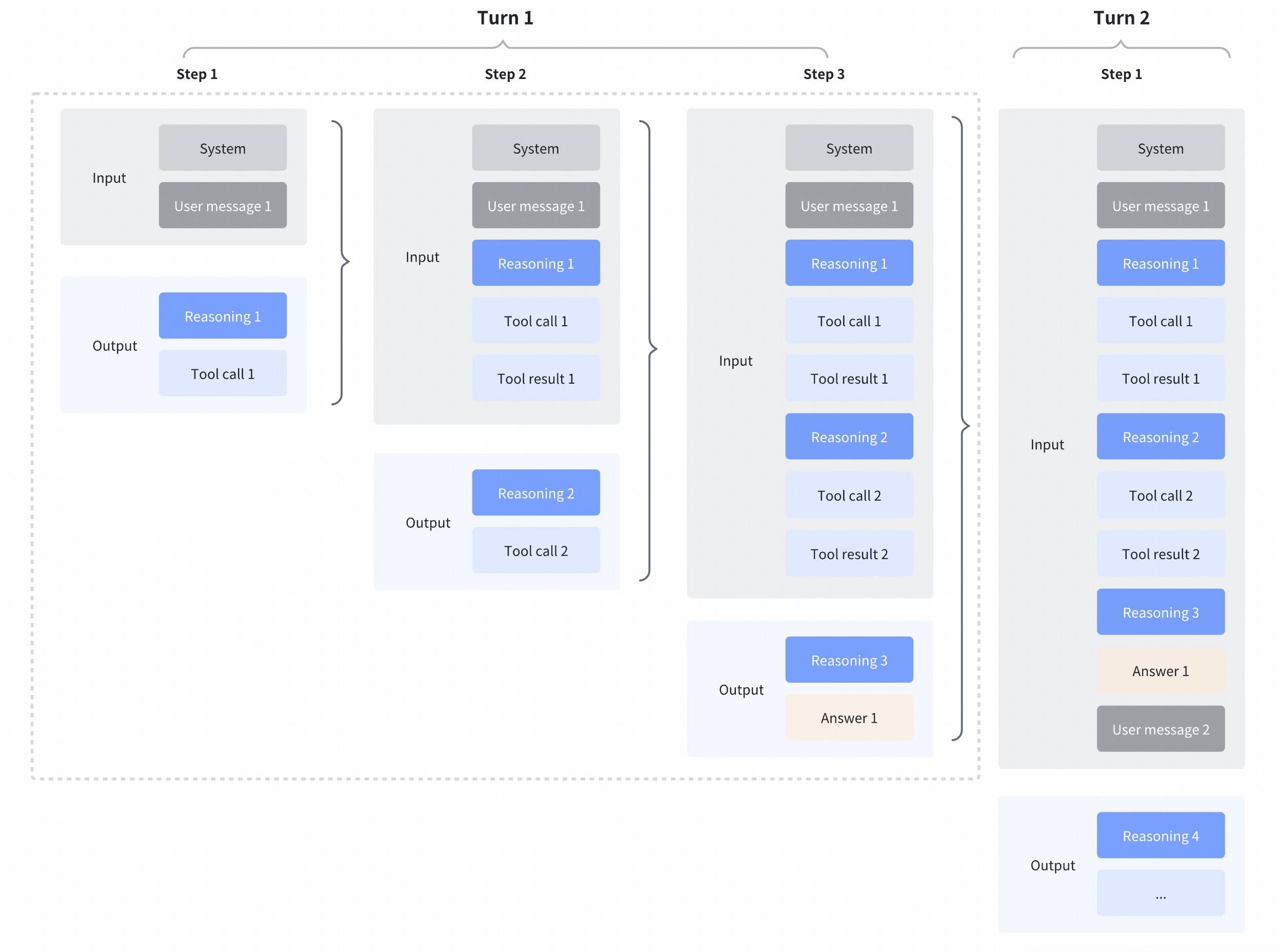
**We introduce a new capability** in coding scenarios: the model can retain **reasoning content from previous assistant turns** in the context. This helps preserve reasoning continuity and conversation integrity, improves model performance, and increases cache hit rates—saving tokens in real tasks.
This capability is **enabled by default** on the **Coding Plan endpoint** and **disabled by default** on the **standard API endpoint**. If you want to enable **Preserved Thinking** in your product (primarily recommended for coding/agent scenarios), you can turn it on for the API endpoint by setting **"clear\_thinking": false**, and **you must return the complete**, unmodified reasoning\_content back to the API.
All consecutive reasoning\_content blocks must **exactly match the original sequence** generated by the model during the initial request. Do not reorder or edit these blocks; otherwise, performance may degrade and cache hit rates may be affected.
The detailed Preserved thinking process is as follows.
## Turn-level Thinking
“Turn-level Thinking” is a capability that **lets you control reasoning computation on a per-turn basis**: within the same session, each request can independently choose to enable or disable thinking. This is a new capability introduced in GLM-4.7, with the following advantages:
* **More flexible cost/latency control:** For lightweight turns like “asking a fact” or “tweaking wording,” you can disable thinking to get faster responses; for heavier tasks like “complex planning,” “multi-constraint reasoning,” or “code debugging,” you can enable thinking to improve accuracy and stability.
* **Smoother multi-turn experience:** The thinking switch can be toggled at any point within a session. The model stays coherent across turns and keeps a consistent output style, making it feel “smarter when things are hard, faster when things are simple.”
* **Better for agent/tool-use scenarios:** On turns that require quick tool execution, you can reduce reasoning overhead; on turns that require making decisions based on tool results, you can turn on deeper thinking—dynamically balancing efficiency and quality.
## Example Usage
This applies to both **Interleaved Thinking** and **Preserved Thinking**—no manual differentiation is required. **Remember to return the historical** `reasoning_content`**to keep the reasoning coherent.**
```python theme={null}
""""Interleaved Thinking + Tool Calling Example"""
import json
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.z.ai/api/paas/v4/",
)
tools = [{"type": "function", "function": {
"name": "get_weather",
"description": "Get weather information",
"parameters": {"type": "object", "properties": {"city": {"type": "string"}}, "required": ["city"]},
}}]
messages = [
{"role": "system", "content": "You are an assistant"},
{"role": "user", "content": "What's the weather like in Beijing?"},
]
# Round 1: the model reasons and then calls a tool
response = client.chat.completions.create(model="glm-4.7", messages=messages, tools=tools, stream=True, extra_body={
"thinking":{
"type":"enabled",
"clear_thinking": False # False for Preserved Thinking
}})
reasoning, content, tool_calls = "", "", []
for chunk in response:
delta = chunk.choices[0].delta
if hasattr(delta, "reasoning_content") and delta.reasoning_content:
reasoning += delta.reasoning_content
if hasattr(delta, "content") and delta.content:
content += delta.content
if hasattr(delta, "tool_calls") and delta.tool_calls:
for tc in delta.tool_calls:
if tc.index >= len(tool_calls):
tool_calls.append({"id": tc.id, "function": {"name": "", "arguments": ""}})
if tc.function.name:
tool_calls[tc.index]["function"]["name"] = tc.function.name
if tc.function.arguments:
tool_calls[tc.index]["function"]["arguments"] += tc.function.arguments
print(f"Reasoning: {reasoning}\nTool calls: {tool_calls}")
# Key: return reasoning_content to keep the reasoning coherent
messages.append({"role": "assistant", "content": content, "reasoning_content": reasoning,
"tool_calls": [{"id": tc["id"], "type": "function", "function": tc["function"]} for tc in tool_calls]})
messages.append({"role": "tool", "tool_call_id": tool_calls[0]["id"],
"content": json.dumps({"weather": "Sunny", "temp": "25°C"})})
# Round 2: the model continues reasoning based on the tool result and responds
response = client.chat.completions.create(model="glm-4.7", messages=messages, tools=tools, stream=True, extra_body={
"thinking":{
"type":"enabled",
"clear_thinking": False # False for Preserved Thinking
}})
reasoning, content = "", ""
for chunk in response:
delta = chunk.choices[0].delta
if hasattr(delta, "reasoning_content") and delta.reasoning_content:
reasoning += delta.reasoning_content
if hasattr(delta, "content") and delta.content:
content += delta.content
print(f"Reasoning: {reasoning}\nReply: {content}")
```