Our most powerful reasoning model, with 355 billion parameters
Cost-Effective Lightweight Strong Performance
High Performance Strong Reasoning Ultra-Fast Response
Lightweight Strong Performance Ultra-Fast Response
Free Strong Performance Excellent for Reasoning Coding & Agents
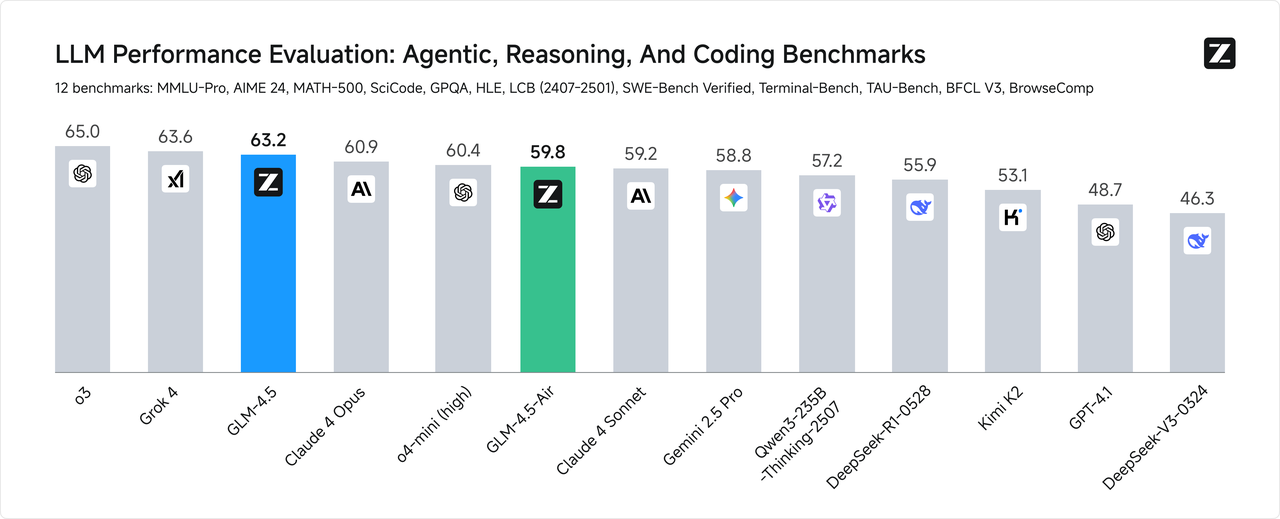
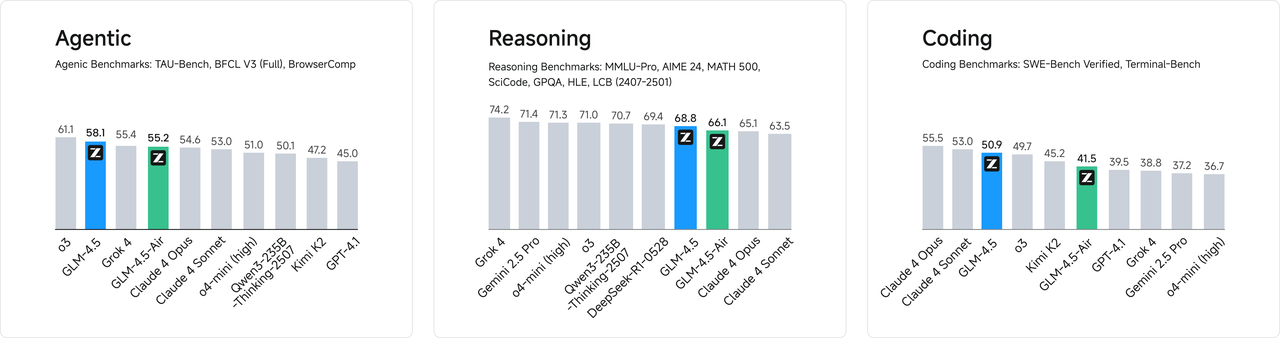 ### **Higher Parameter Efficiency**
GLM-4.5 has half the number of parameters of DeepSeek-R1 and one-third that of Kimi-K2, yet it outperforms them on multiple standard benchmark tests. This is attributed to the higher parameter efficiency of GLM architecture. Notably, GLM-4.5-Air, with 106 billion total parameters and 12 billion active parameters, achieves a significant breakthrough—surpassing models such as Gemini 2.5 Flash, Qwen3-235B, and Claude 4 Opus on reasoning benchmarks like Artificial Analysis, ranking among the top three domestic models in performance.
On charts such as SWE-Bench Verified, the GLM-4.5 series lies on the Pareto frontier for performance-to-parameter ratio, demonstrating that at the same scale, the GLM-4.5 series delivers optimal performance.
### **Higher Parameter Efficiency**
GLM-4.5 has half the number of parameters of DeepSeek-R1 and one-third that of Kimi-K2, yet it outperforms them on multiple standard benchmark tests. This is attributed to the higher parameter efficiency of GLM architecture. Notably, GLM-4.5-Air, with 106 billion total parameters and 12 billion active parameters, achieves a significant breakthrough—surpassing models such as Gemini 2.5 Flash, Qwen3-235B, and Claude 4 Opus on reasoning benchmarks like Artificial Analysis, ranking among the top three domestic models in performance.
On charts such as SWE-Bench Verified, the GLM-4.5 series lies on the Pareto frontier for performance-to-parameter ratio, demonstrating that at the same scale, the GLM-4.5 series delivers optimal performance.
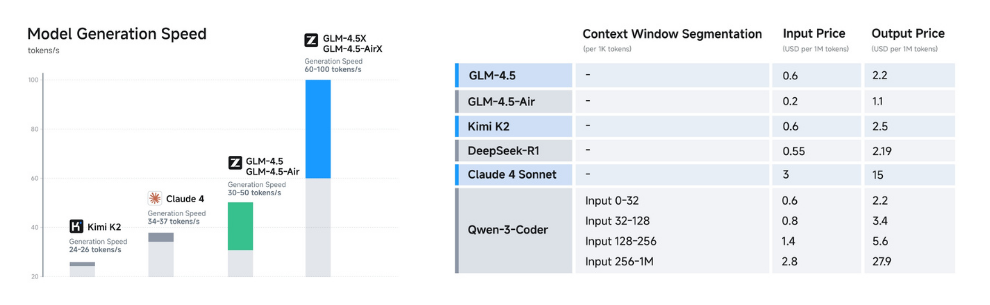
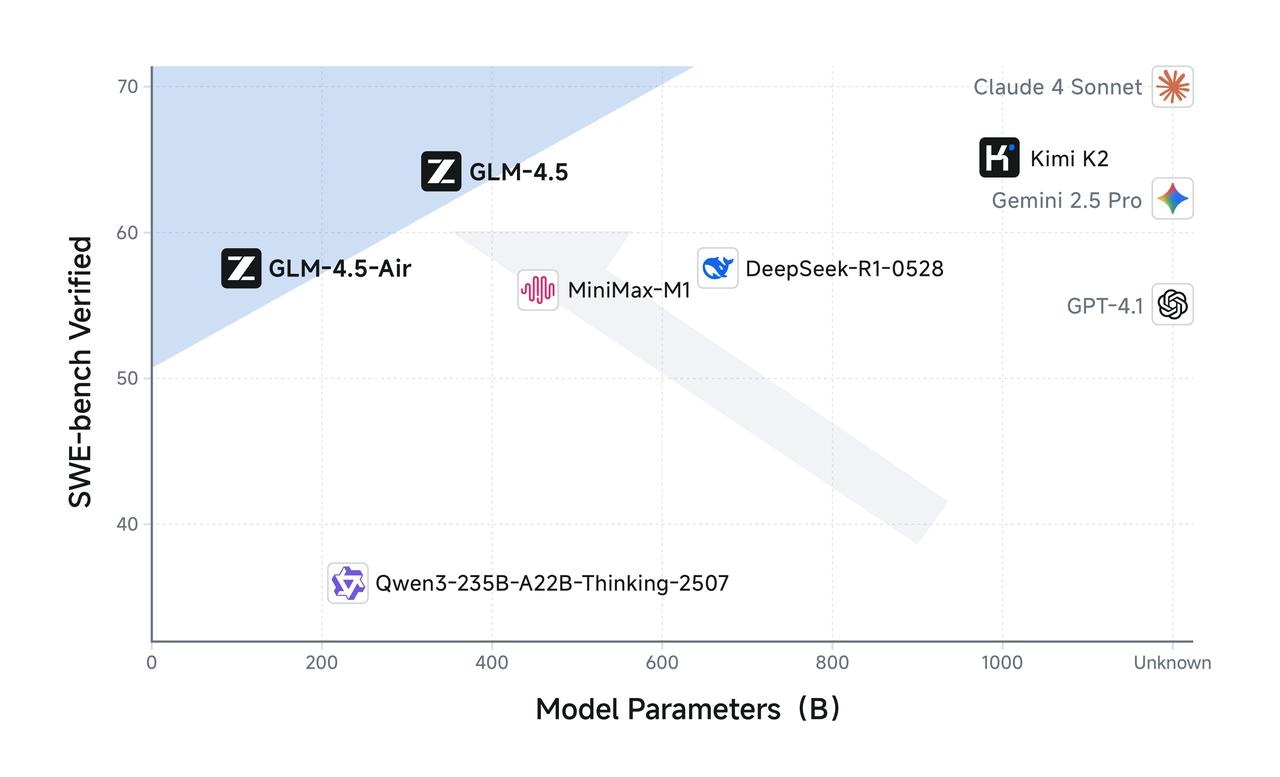 ### **Low Cost, High Speed**
Beyond performance optimization, the GLM-4.5 series also achieves breakthroughs in cost and efficiency, resulting in pricing far lower than mainstream models: API call costs are as low as \$0.2 per million input tokens and \$1.1 per million output tokens.
At the same time, the high-speed version demonstrates a generation speed exceeding 100 tokens per second in real-world tests, supporting low-latency and high-concurrency deployment scenarios—balancing cost-effectiveness with user interaction experience.
### **Low Cost, High Speed**
Beyond performance optimization, the GLM-4.5 series also achieves breakthroughs in cost and efficiency, resulting in pricing far lower than mainstream models: API call costs are as low as \$0.2 per million input tokens and \$1.1 per million output tokens.
At the same time, the high-speed version demonstrates a generation speed exceeding 100 tokens per second in real-world tests, supporting low-latency and high-concurrency deployment scenarios—balancing cost-effectiveness with user interaction experience.
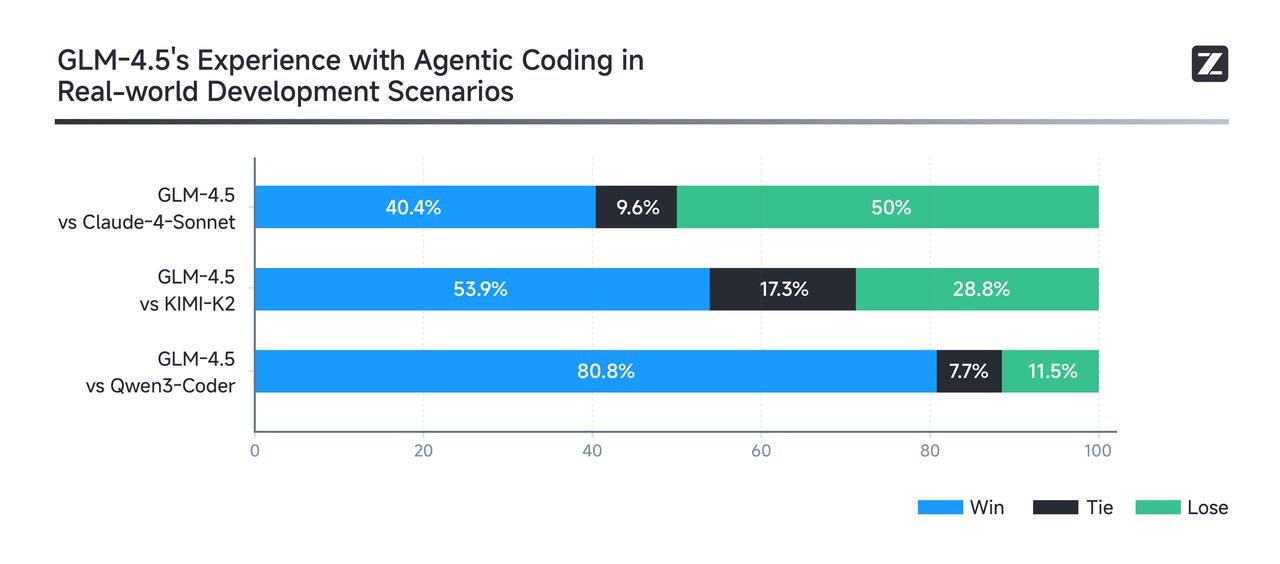
 ### **Real-World Evaluation**
Real-world performance matters more than leaderboard rankings. To evaluate GLM-4.5’s effectiveness in practical Agent Coding scenarios, we integrated it into Claude Code and benchmarked it against Claude 4 Sonnet, Kimi-K2, and Qwen3-Coder.
The evaluation consisted of 52 programming and development tasks spanning six major domains, executed in isolated container environments with multi-turn interaction tests.
As shown in the results (below), GLM-4.5 demonstrates a strong competitive advantage over other open-source models, particularly in tool invocation reliability and task completion rate. While there remains room for improvement compared to Claude 4 Sonnet, GLM-4.5 delivers a largely comparable experience in most scenarios.
To ensure transparency, we have released all [52 test problems along with full agent trajectories](https://huggingface.co/datasets/zai-org/CC-Bench-trajectories) for industry validation and reproducibility.
### **Real-World Evaluation**
Real-world performance matters more than leaderboard rankings. To evaluate GLM-4.5’s effectiveness in practical Agent Coding scenarios, we integrated it into Claude Code and benchmarked it against Claude 4 Sonnet, Kimi-K2, and Qwen3-Coder.
The evaluation consisted of 52 programming and development tasks spanning six major domains, executed in isolated container environments with multi-turn interaction tests.
As shown in the results (below), GLM-4.5 demonstrates a strong competitive advantage over other open-source models, particularly in tool invocation reliability and task completion rate. While there remains room for improvement compared to Claude 4 Sonnet, GLM-4.5 delivers a largely comparable experience in most scenarios.
To ensure transparency, we have released all [52 test problems along with full agent trajectories](https://huggingface.co/datasets/zai-org/CC-Bench-trajectories) for industry validation and reproducibility.
 ## Usage
## Usage