Default Thinking Behaviour
Thinking is activated by default in GLM-5.2 GLM-5.1 GLM-5 GLM-4.7 series, different from the default hybrid thinking in GLM-4.6.If you want to disable thinking, use:
Interleaved thinking
We support interleaved thinking by default (supported since GLM-4.5), allowing GLM to think between tool calls and after receiving tool results. This enables more complex, step-by-step reasoning: interpreting each tool output before deciding what to do next, chaining multiple tool calls with reasoning steps, and making finer-grained decisions based on intermediate results. The detailed interleaved thinking process is as follows.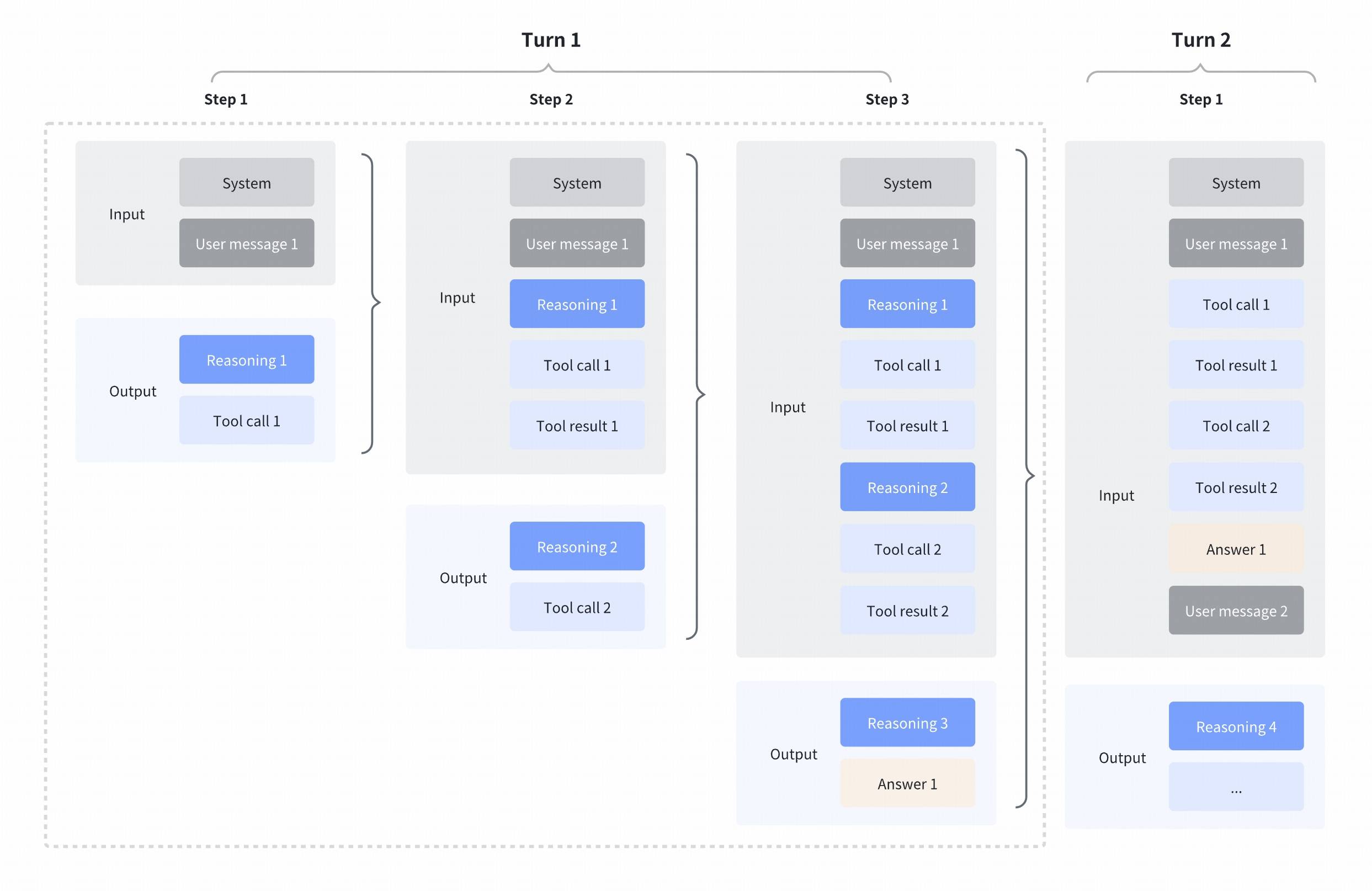
Preserved thinking
We introduce a new capability in coding scenarios: the model can retain reasoning content from previous assistant turns in the context. This helps preserve reasoning continuity and conversation integrity, improves model performance, and increases cache hit rates—saving tokens in real tasks.This capability is enabled by default on the Coding Plan endpoint and disabled by default on the standard API endpoint. If you want to enable Preserved Thinking in your product (primarily recommended for coding/agent scenarios), you can turn it on for the API endpoint by setting “clear_thinking”: false, and you must return the complete, unmodified reasoning_content back to the API.All consecutive reasoning_content blocks must exactly match the original sequence generated by the model during the initial request. Do not reorder or edit these blocks; otherwise, performance may degrade and cache hit rates may be affected.
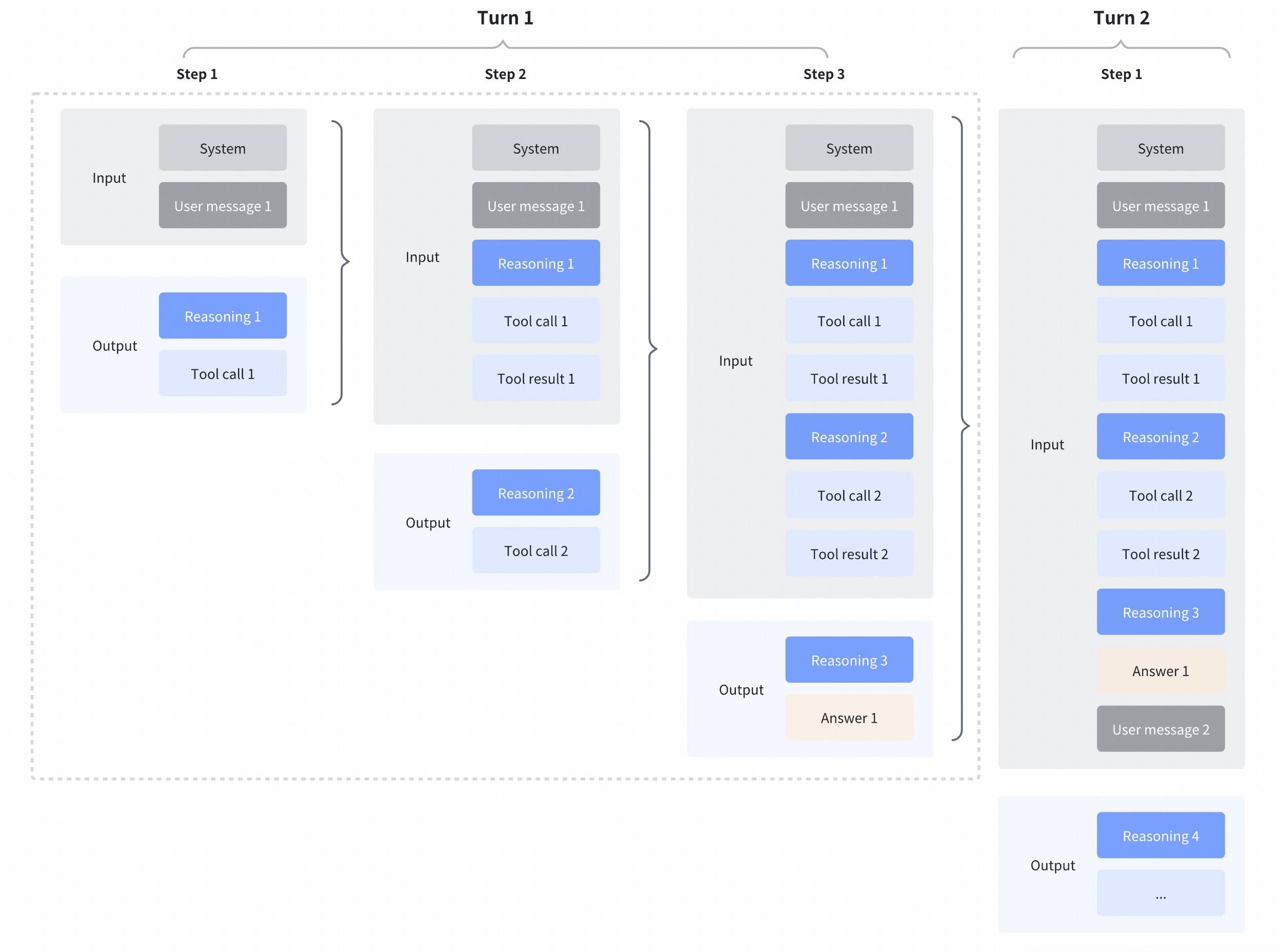
Turn-level Thinking
“Turn-level Thinking” is a capability that lets you control reasoning computation on a per-turn basis: within the same session, each request can independently choose to enable or disable thinking. This is a new capability introduced in GLM-4.7, with the following advantages:- More flexible cost/latency control: For lightweight turns like “asking a fact” or “tweaking wording,” you can disable thinking to get faster responses; for heavier tasks like “complex planning,” “multi-constraint reasoning,” or “code debugging,” you can enable thinking to improve accuracy and stability.
- Smoother multi-turn experience: The thinking switch can be toggled at any point within a session. The model stays coherent across turns and keeps a consistent output style, making it feel “smarter when things are hard, faster when things are simple.”
- Better for agent/tool-use scenarios: On turns that require quick tool execution, you can reduce reasoning overhead; on turns that require making decisions based on tool results, you can turn on deeper thinking—dynamically balancing efficiency and quality.
Example Usage
This applies to both Interleaved Thinking and Preserved Thinking—no manual differentiation is required. Remember to return the historicalreasoning_contentto keep the reasoning coherent.