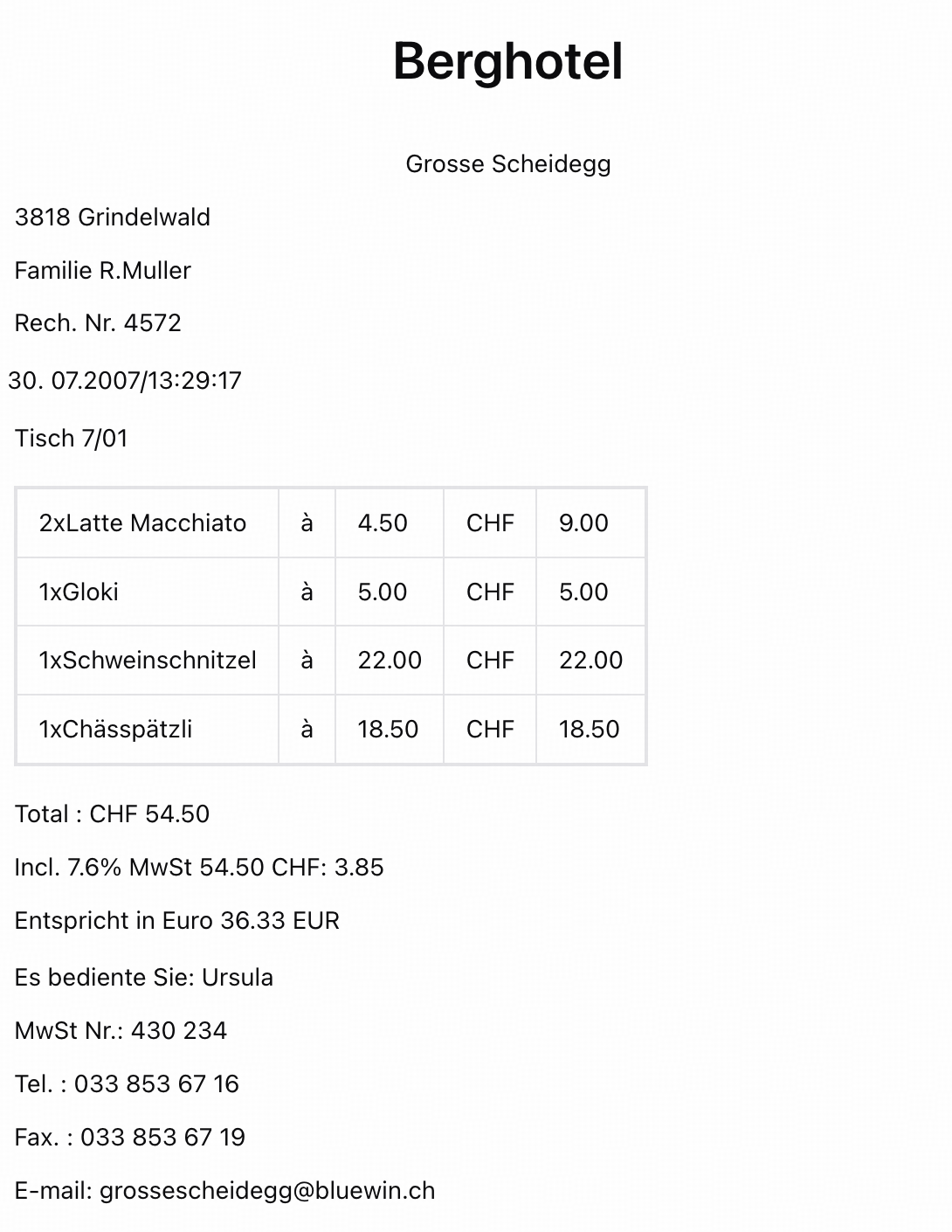
Input
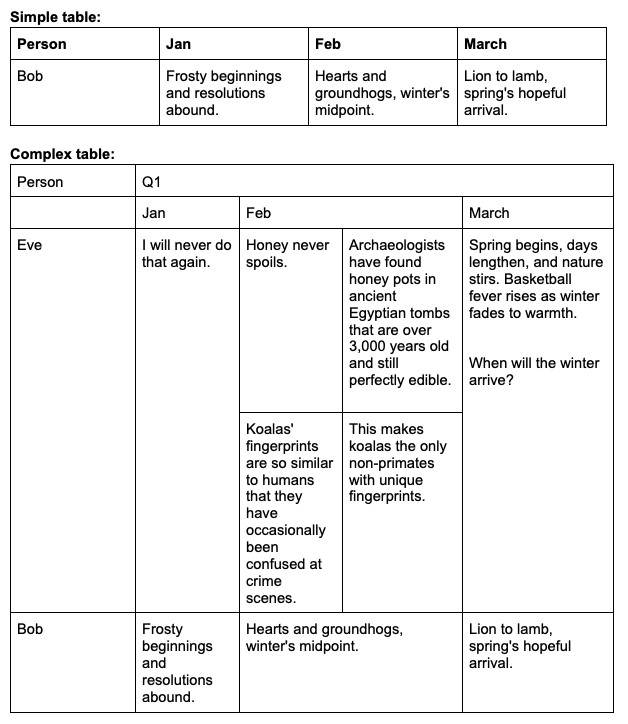
Output
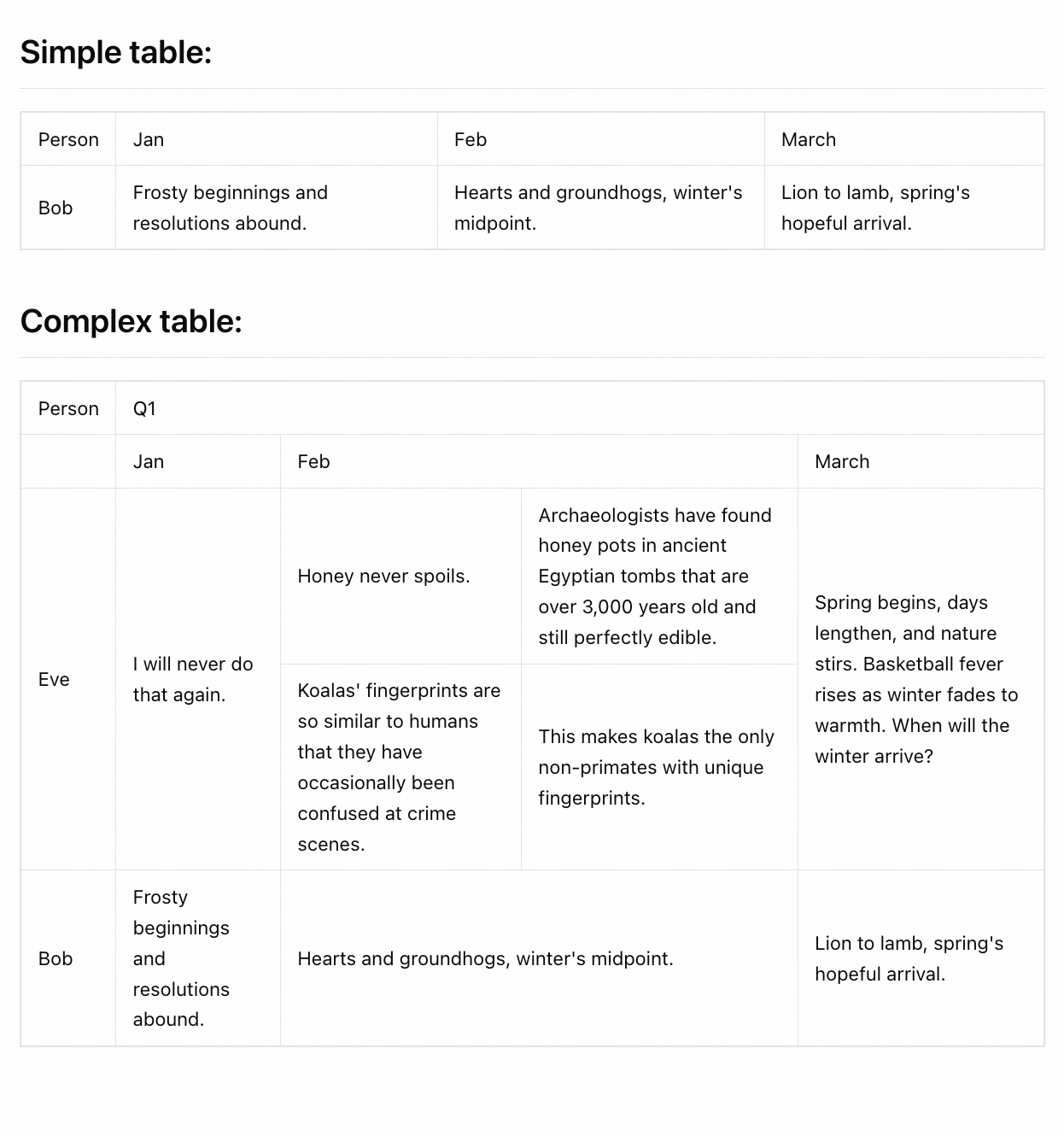
Text Recognition
Table Recognition
Information Structuring
Retrieval-Augmented Generation (RAG)
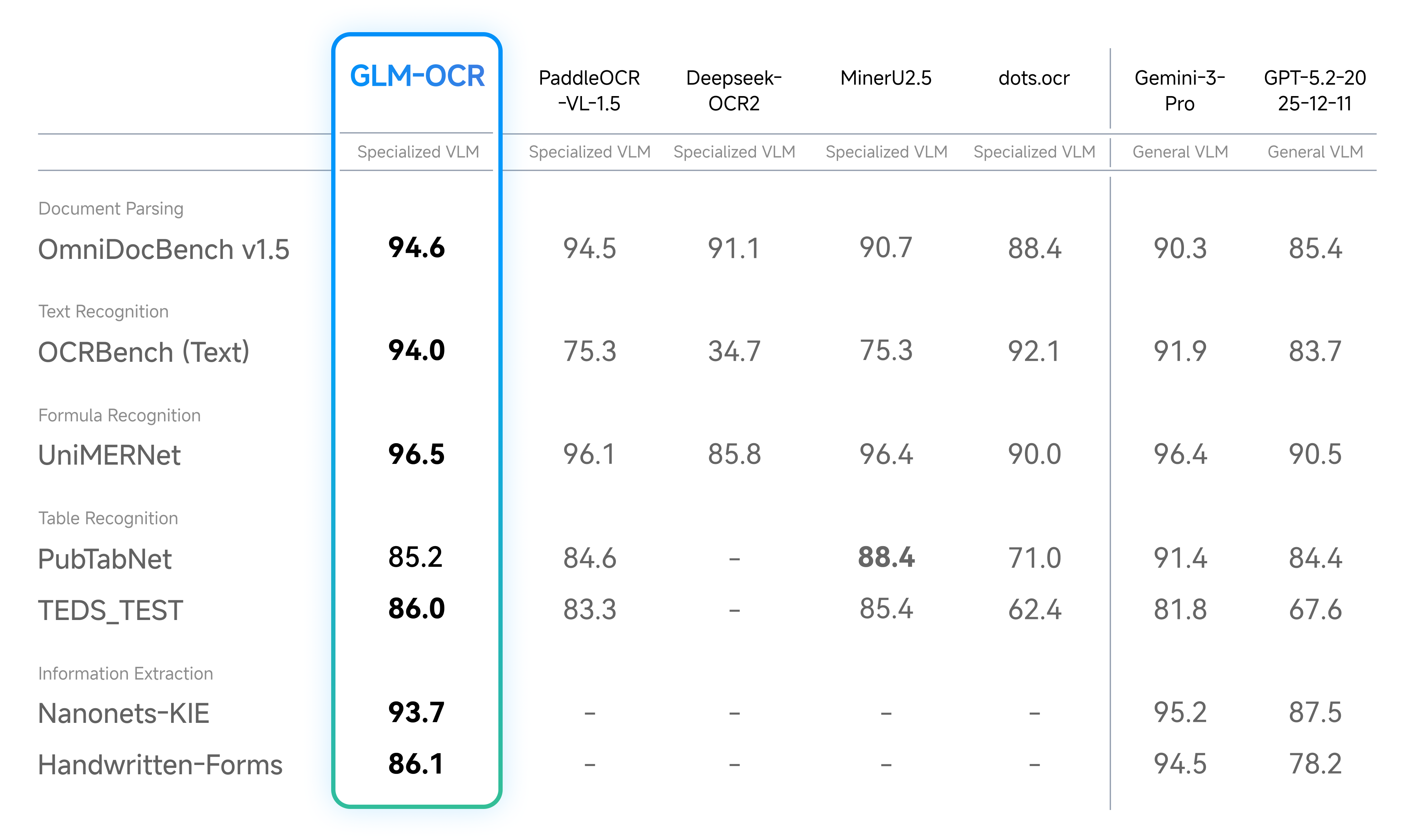 Beyond public benchmarks, we conducted internal evaluations across six core real-world scenarios. Results show GLM-OCR delivers significant advantages across dimensions including code documentation, real-world tables, handwriting, multilingual text, seal recognition, and invoice extraction.
Beyond public benchmarks, we conducted internal evaluations across six core real-world scenarios. Results show GLM-OCR delivers significant advantages across dimensions including code documentation, real-world tables, handwriting, multilingual text, seal recognition, and invoice extraction.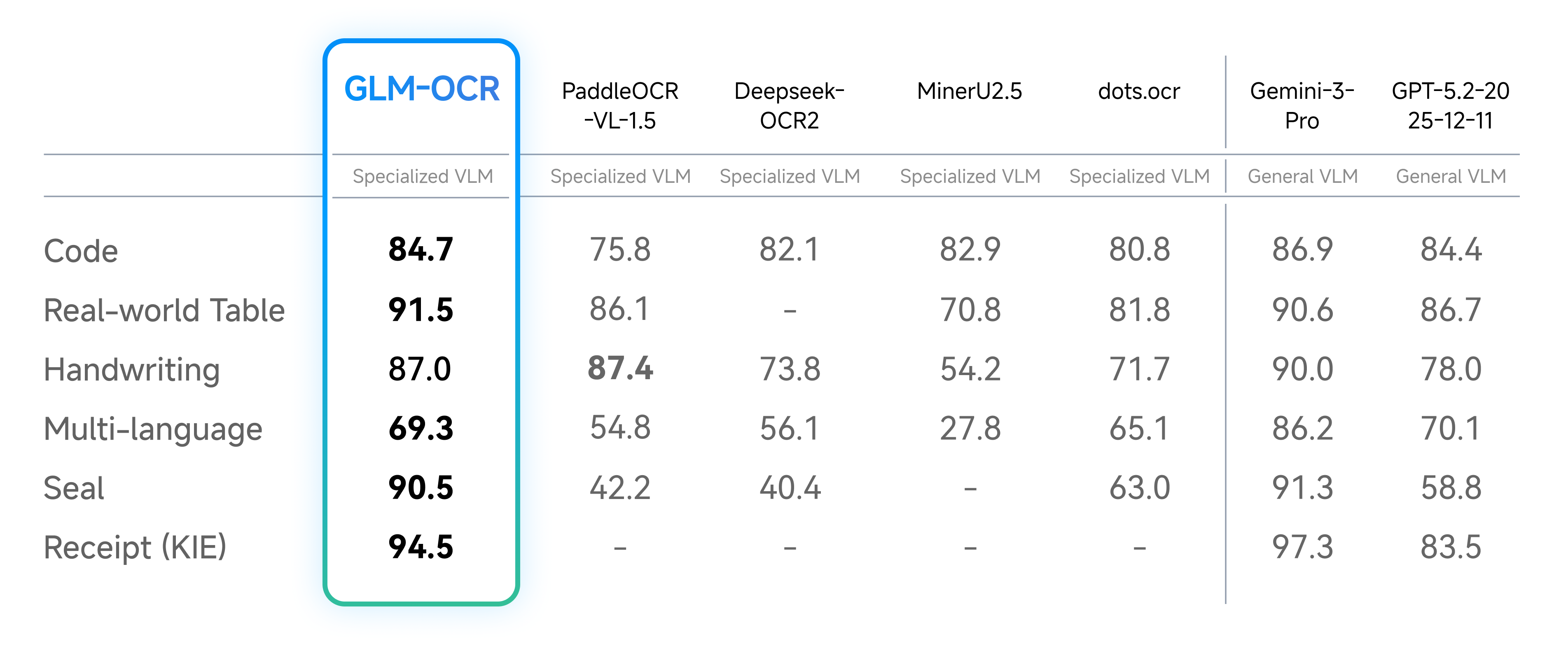
 Pricing is uniform for both API input and output, costing just $0.03 per million tokens.
Pricing is uniform for both API input and output, costing just $0.03 per million tokens.