Overview
GLM-Image is Z.AI’s new flagship image generation model, which adopts an original hybrid architecture of “autoregressive + diffusion decoder”, taking into account both global instruction understanding and local detail portrayal, overcoming the challenges in generating knowledge-intensive scenarios such as posters, PPTs, and science popularization diagrams. It represents an important exploration of the new generation of “cognitive generative” technology paradigm represented by Nano Banana Pro.Price
$0.015 / image
Input Modality
Text
Output Modality
Image
Resolution
Supports 1:1, 3:4, 4:3, 16:9, etc.
Please note that the output of the GLM-Image model is an image URL. You need to download the image via the provided URL.
Usage
Commercial poster
Commercial poster
It can generate festival posters and commercial promotional images with complete composition, clear visual hierarchy, and prominent overall design sense, support the precise embedding and stable presentation of text content, and is suitable for various commercial scenarios such as brand communication and market promotion.
Popular science illustration
Popular science illustration
More adept at creating popular science illustrations and schematic diagrams of principles that include complex logical relationships, process descriptions, and text annotations, capable of clearly and accurately conveying the knowledge structure and core information while ensuring the aesthetic appeal of the visuals.
Multi-panel drawing
Multi-panel drawing
When generating multi-panel images such as e-commerce display images and story comics, GLM-Image can effectively maintain the consistency of the overall content style and the main subject’s image, while significantly improving the accuracy of text generation in multiple locations to ensure content coherence and unified expression.
Resources
- API Documentation: Learn how to call the API.
Introducting GLM-Image
Architectural Innovation: Understand Instructions, Write Correctly
GLM-image is an important exploration of ours in the technological paradigm of “cognitive generative” technology, and it is the first open-source industrial-grade discrete autoregressive image generation model.GLM-Image introduces a hybrid architecture of “autoregressive + diffusion decoder”, integrating a 9B autoregressive model with a 7B DiT diffusion decoder. The former leverages the advantages of its language model base, focusing on enhancing semantic understanding of instructions and global composition of images; the latter, in conjunction with the text encoder of Glyph Encoder, focuses on restoring high-frequency details of images and text strokes, thereby improving the model’s “forgetting characters while writing” phenomenon.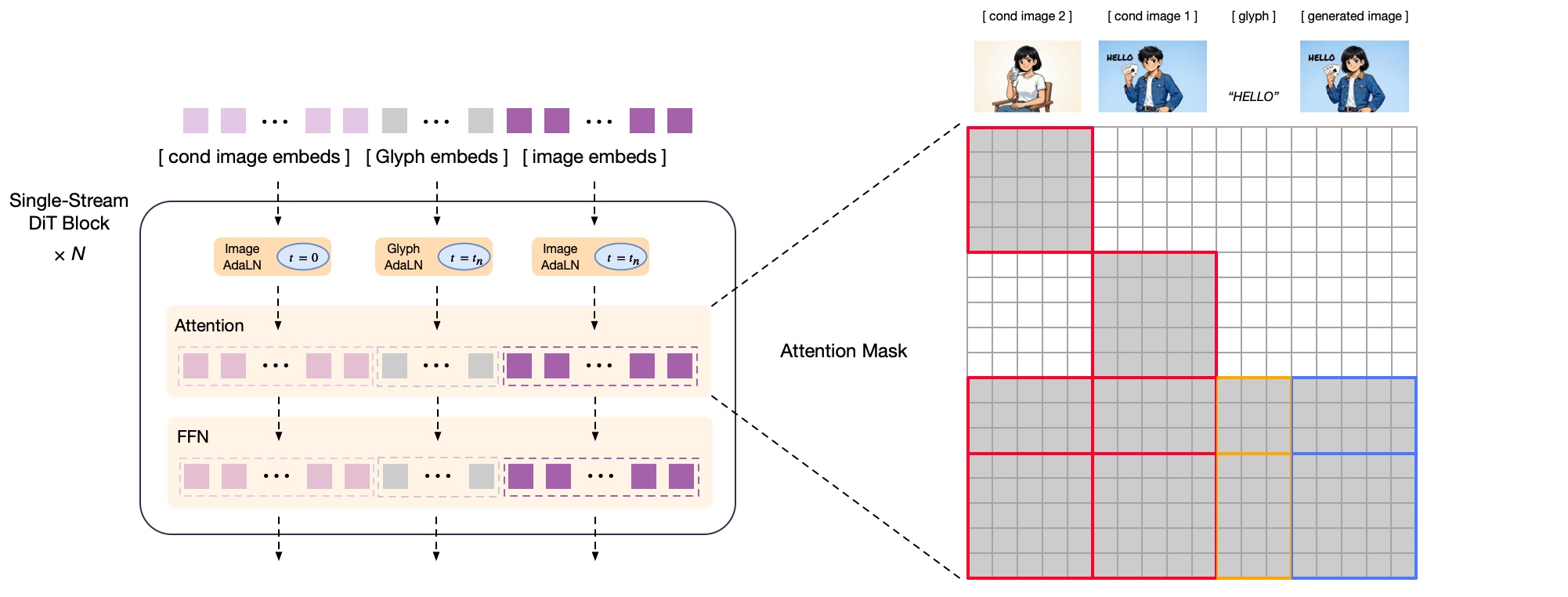 decoder formulation
decoder formulation
decoder formulationOpen-source SoTA: More adept at text-intensive generation tasks
Based on the above architectural innovation, GLM-Image has reached the open-source SOTA level in the authoritative leaderboard for text rendering.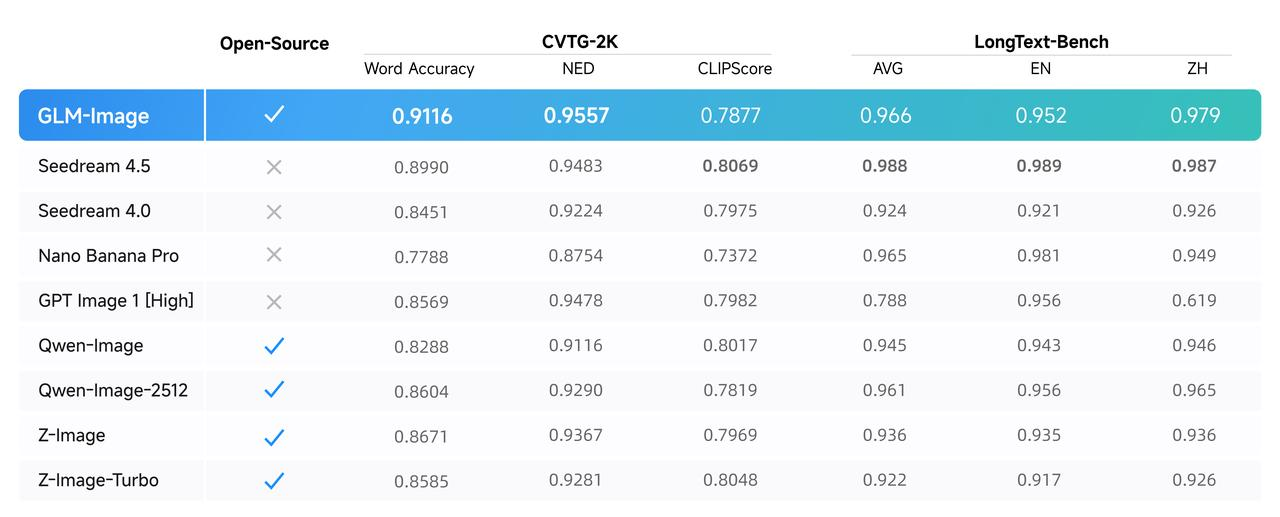 The CVTG-2K (Complex Visual Text Generation) leaderboard primarily evaluates the accuracy of models in simultaneously generating multiple text instances within an image. In terms of multi-region text generation accuracy, GLM-Image ranks first among open-source models, with a Word Accuracy score of 0.9116. On the NED (Normalized Edit Distance) metric, GLM-Image also leads with a score of 0.9557, indicating that the text it generates is highly consistent with the target text, with fewer typos and omissions.The LongText-Bench (Long Text Rendering) leaderboard evaluates the accuracy of models in rendering long texts and multi-line texts, covering 8 text-intensive scenarios such as signboards, posters, PPTs, dialog boxes, etc., and separately conducts bilingual tests in Chinese and English. GLM-Image ranked first among open-source models with scores of 0.9524 in English and 0.9788 in Chinese.
The CVTG-2K (Complex Visual Text Generation) leaderboard primarily evaluates the accuracy of models in simultaneously generating multiple text instances within an image. In terms of multi-region text generation accuracy, GLM-Image ranks first among open-source models, with a Word Accuracy score of 0.9116. On the NED (Normalized Edit Distance) metric, GLM-Image also leads with a score of 0.9557, indicating that the text it generates is highly consistent with the target text, with fewer typos and omissions.The LongText-Bench (Long Text Rendering) leaderboard evaluates the accuracy of models in rendering long texts and multi-line texts, covering 8 text-intensive scenarios such as signboards, posters, PPTs, dialog boxes, etc., and separately conducts bilingual tests in Chinese and English. GLM-Image ranked first among open-source models with scores of 0.9524 in English and 0.9788 in Chinese.
The CVTG-2K (Complex Visual Text Generation) leaderboard primarily evaluates the accuracy of models in simultaneously generating multiple text instances within an image. In terms of multi-region text generation accuracy, GLM-Image ranks first among open-source models, with a Word Accuracy score of 0.9116. On the NED (Normalized Edit Distance) metric, GLM-Image also leads with a score of 0.9557, indicating that the text it generates is highly consistent with the target text, with fewer typos and omissions.The LongText-Bench (Long Text Rendering) leaderboard evaluates the accuracy of models in rendering long texts and multi-line texts, covering 8 text-intensive scenarios such as signboards, posters, PPTs, dialog boxes, etc., and separately conducts bilingual tests in Chinese and English. GLM-Image ranked first among open-source models with scores of 0.9524 in English and 0.9788 in Chinese.Examples
- High-Quality Portraits
- Commercial Poster
Prompt
A Hasselblad film–style portrait set in soft indoor lighting. A long-haired
woman stands within gentle shadows, while branches outside the window
sway in the breeze, casting dappled light across her face and shoulders.
Sheer fabric drapes softly in the background, creating a hazy, romantic
atmosphere. Rim lighting outlines her relaxed, natural posture, and her
slightly tousled hair lifts gently in the air, each strand catching
subtle highlights from the sunlight. A close-up composition captures
the moment she gazes deeply into the camera. Her skin appears clear and
finely textured under high exposure and strong light–shadow contrast.
The background is softly blurred, with bloom and diffusion blending into
a dreamy glow. Film-like grain and delicate reflections add richness and
realism, freezing a poetic instant of afternoon light and breeze.
Generated Image



Quick Start
- cURL
- Python
- Java