Overview
GLM-5V-Turbo is Z.AI’s first multimodal coding foundation model, built for vision-based coding tasks. It can natively process multimodal inputs such as images, video, and text, while also excelling at long-horizon planning, complex coding, and action execution. Deeply optimized for agent workflows, it works seamlessly with agents such as Claude Code and OpenClaw to complete the full loop of “understand the environment → plan actions → execute tasks”.Positioning
Multimodal Coding Model
Input Modality
Video / Image / Text / File
Output Modality
Text
Context Length
200K
Maximum Output Tokens
128K
Capability
Thinking Mode
Offering multiple thinking modes for different scenarios
Vision Comprehension
Powerful vision understanding capabilities, with support for images, video, and files
Streaming Output
Support real-time streaming responses to enhance user interaction experience
Function Call
Powerful tool invocation capabilities, enabling integration with various external toolsets
Context Caching
Intelligent caching mechanism to optimize performance in long conversations
Usage
Frontend Recreation
Frontend Recreation
Send a design mockup or reference image, and the model can directly understand the layout, color palette, component hierarchy, and interaction logic, then generate a complete runnable frontend project. For wireframes, it reconstructs structure and functionality; for high-fidelity designs, it aims for pixel-level visual consistency.
GUI Autonomous Exploration and Recreation
GUI Autonomous Exploration and Recreation
Works with frameworks such as Claude Code to autonomously browse target websites, map page transitions, collect visual assets and interaction details, and directly generate code based on the exploration results—upgrading from “recreating from a screenshot” to “recreating through autonomous exploration.”
Code Debugging
Code Debugging
Supports inputting screenshots of buggy pages, automatically identifying rendering issues such as layout misalignment, component overlap, and color mismatches, helping locate frontend problems and generate fix code to improve debugging efficiency.
OpenClaw
OpenClaw
After integrating GLM-5V-Turbo, OpenClaw can understand webpage layouts, GUI elements, and chart information, helping the agent handle complex real-world tasks that combine perception, planning, and execution.
Resources
- API Documentation: Learn how to call the API.
Introducing GLM-5V-Turbo
Multimodal Coding Foundation
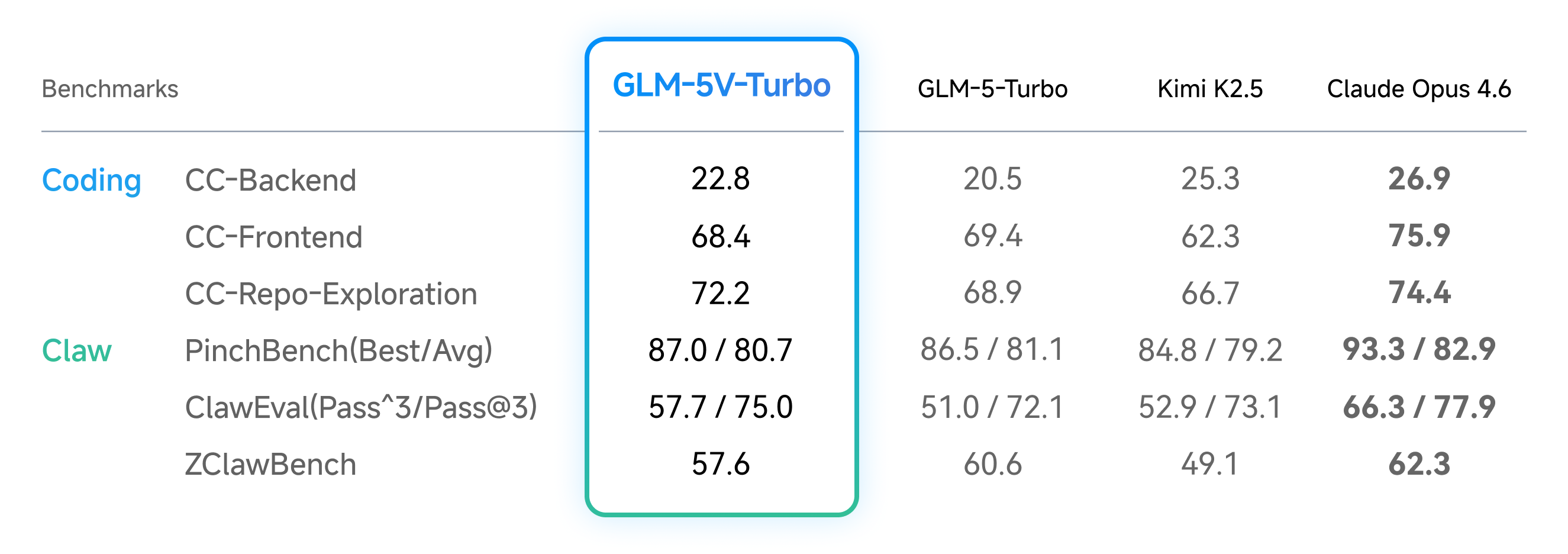
Across benchmarks for multimodal coding and agentic tasks, as well as pure-text coding, GLM-5V-Turbo delivers strong performance with a smaller model size.
- Multimodal Coding and Agentic Tasks
- Pure-Text Coding Tasks
In multimodal coding and agentic tasks, GLM-5V-Turbo achieved leading results across benchmarks for design-to-code generation, visual code generation, multimodal retrieval and question answering, and visual exploration. It also delivered strong performance on benchmarks such as AndroidWorld and WebVoyager, which evaluate an agent’s ability to operate in real GUI environments.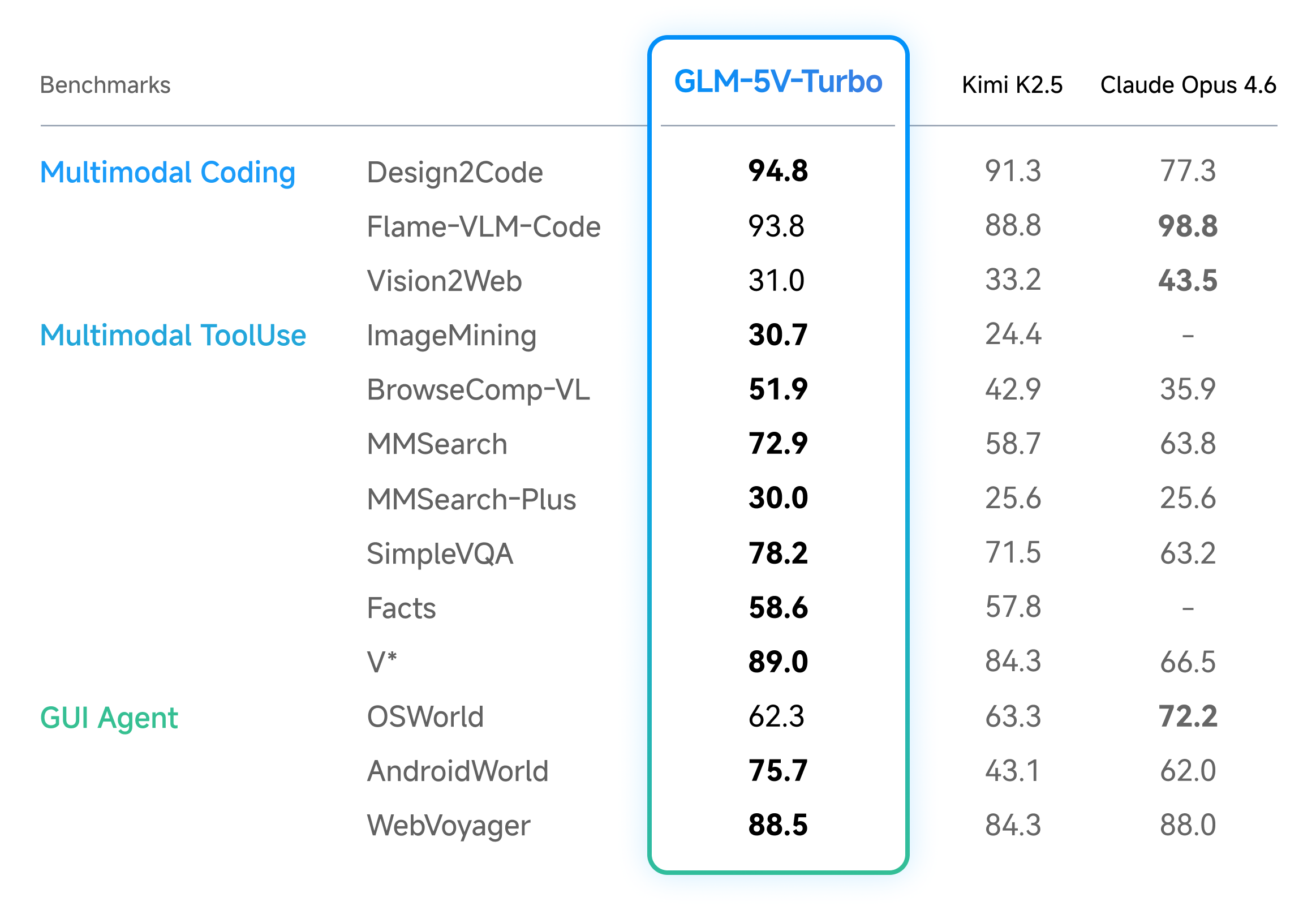
Systematic Upgrades Across Four Layers
GLM-5V-Turbo combines strong vision and coding capabilities while achieving leading performance with a smaller parameter size, powered by systematic upgrades across model architecture, training methods, data construction, and tooling:
- Native Multimodal Fusion: From pretraining through post-training, the model continuously strengthens visual-text alignment. Combined with the new CogViT vision encoder and an inference-friendly MTP architecture, it improves multimodal understanding and reasoning efficiency.
- 30+ Task Joint Reinforcement Learning: During RL, the model is jointly optimized across 30+ task types, spanning STEM, grounding, video, GUI agents, and coding agents, resulting in more robust gains in perception, reasoning, and agentic execution.
- Agentic Data and Task Construction: To address the scarcity of agent data and the difficulty of verification, we built a multi-level, controllable, and verifiable data system, and injected agentic meta-capabilities during pretraining to strengthen action prediction and execution.
- Expanded Multimodal Toolchain: Adds multimodal tools such as box drawing, screenshots, and webpage reading (including image understanding), extending agent capabilities from pure text to visual interaction and supporting a more complete perception–planning–execution loop.
Official Skills
Beyond vision-based coding and Claw-style tasks, GLM-5V-Turbo also shows major gains in a broader range of agentic scenarios, including multimodal search, deep research, GUI agents, and perceptual grounding. To support these use cases, we provide a set of official Skills.Image Captioning
Image Captioning
The ability to automatically analyze image content and generate natural-language descriptions; it can not only identify objects in an image, but also understand relationships between objects, scene atmosphere, and actions, turning them into accurate and fluent textual descriptions
Visual Grounding
Visual Grounding
The ability to precisely locate the corresponding object or region in an image based on a natural-language description; it establishes alignment between text and visual pixels, typically marking the target location with a bounding box, enabling more grounded interactions and assisting with fine-grained image analysis
Document-Grounded Writing
Document-Grounded Writing
The ability to understand and extract key information from user-provided documents (such as PDFs and Word files) and then generate text in a specified format; this ensures the output remains tightly grounded in the document content, making it useful for document interpretation, report generation, news writing, or proposal drafting
Resume Screening
Resume Screening
The ability to read candidate resumes and intelligently compare them against job requirements; it can quickly extract key information such as education, work experience, and skill tags, assess candidate-job fit, and provide rankings or recommendations, significantly improving recruiting efficiency
Prompt Generation
Prompt Generation
The ability to automatically generate high-quality, structured prompts based on reference images/videos and the user’s intended goal; by understanding the content and characteristics of the image/video, refining wording, and adding relevant detail, it produces instructions that are easier for AI models to follow, leading to more accurate and higher-quality image/video generation results
Examples
- Web Page Coding
- Website Generation
- Document Comprehension & Writing
- Video Object Tracking
Input
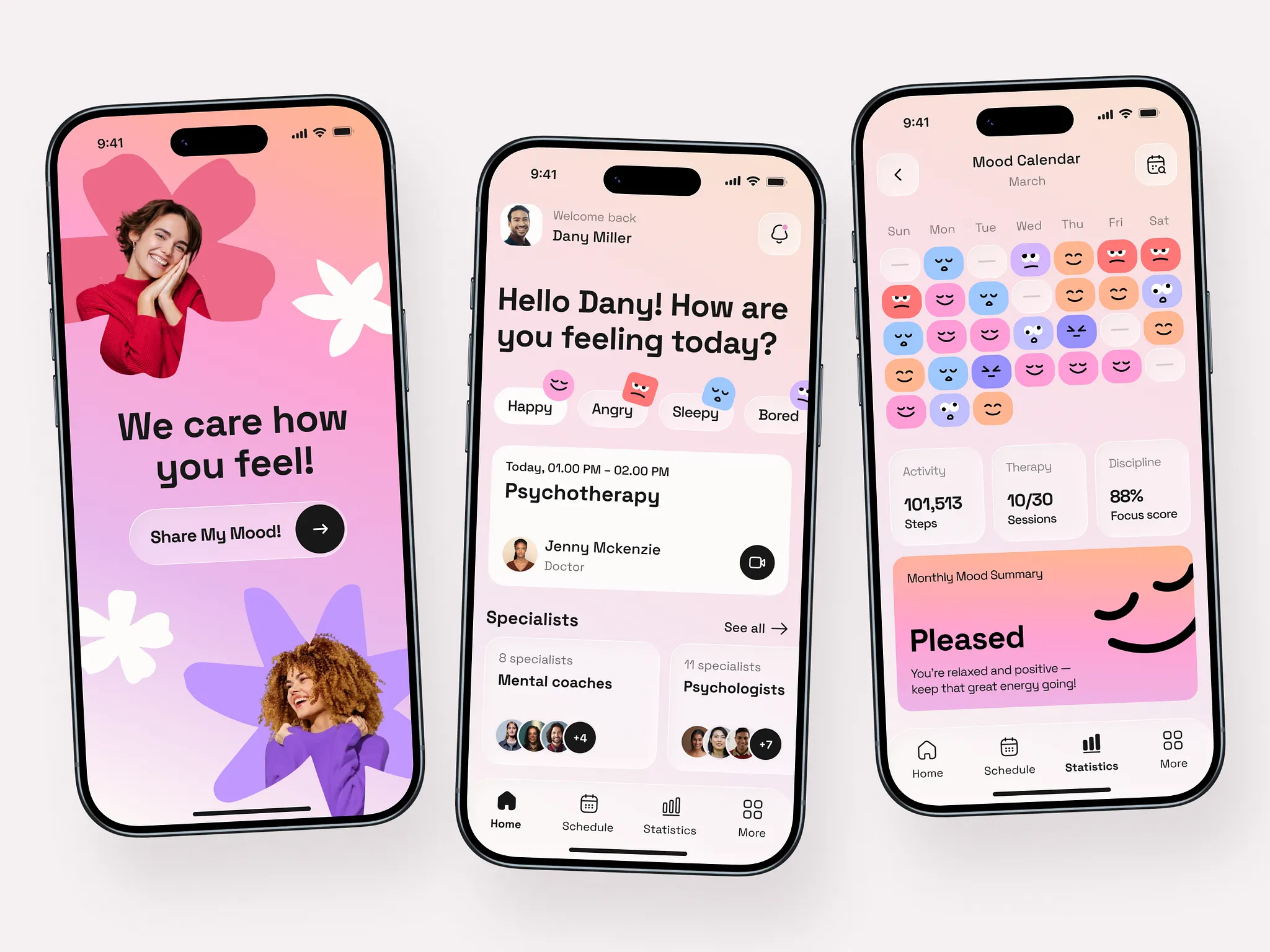
Please recreate the mobile pages based on the design mockups in the images. The left side shows the welcome page, and the center shows the homepage image. You will also need to create mockups for the remaining two pages.
Output
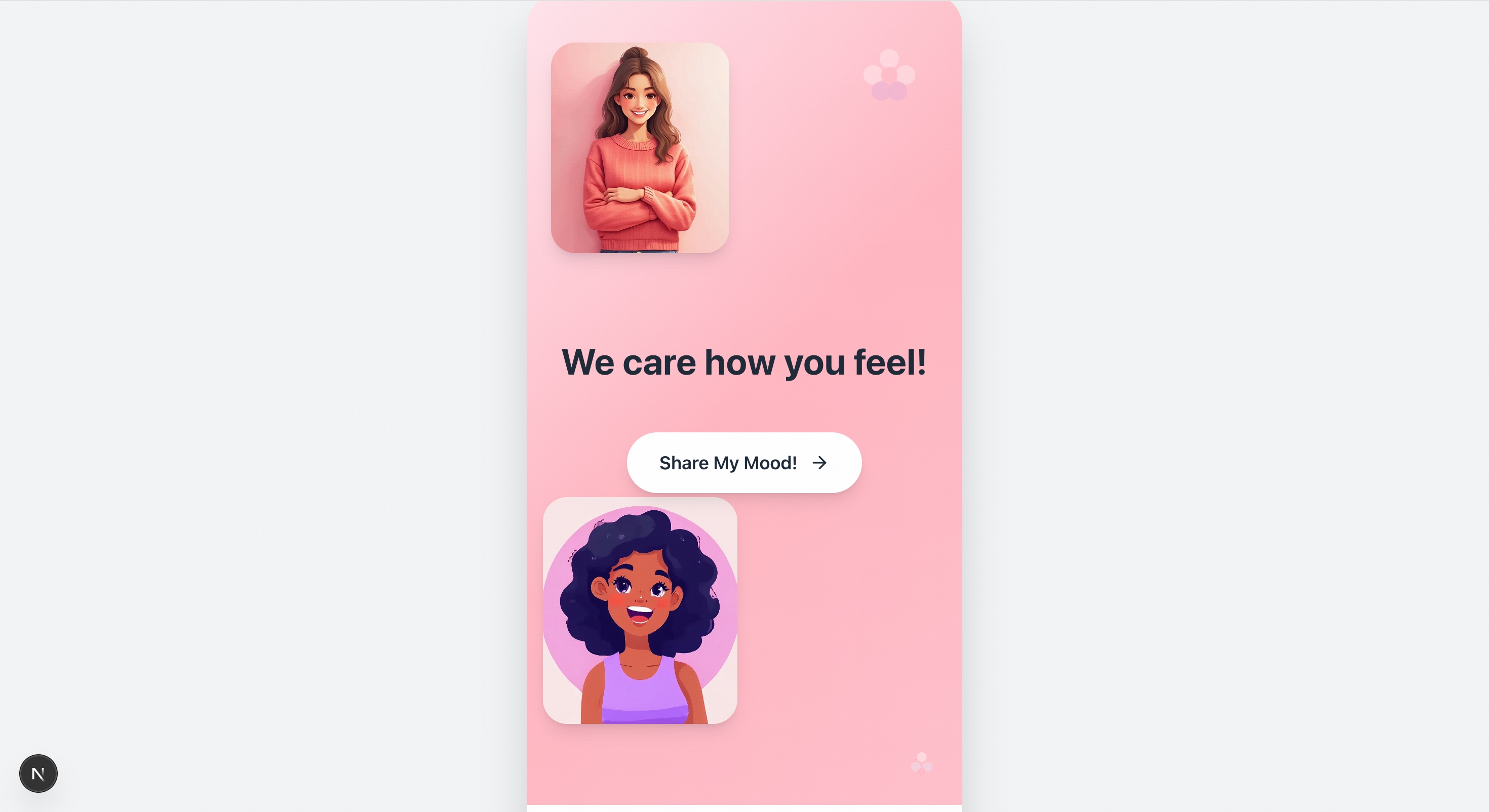
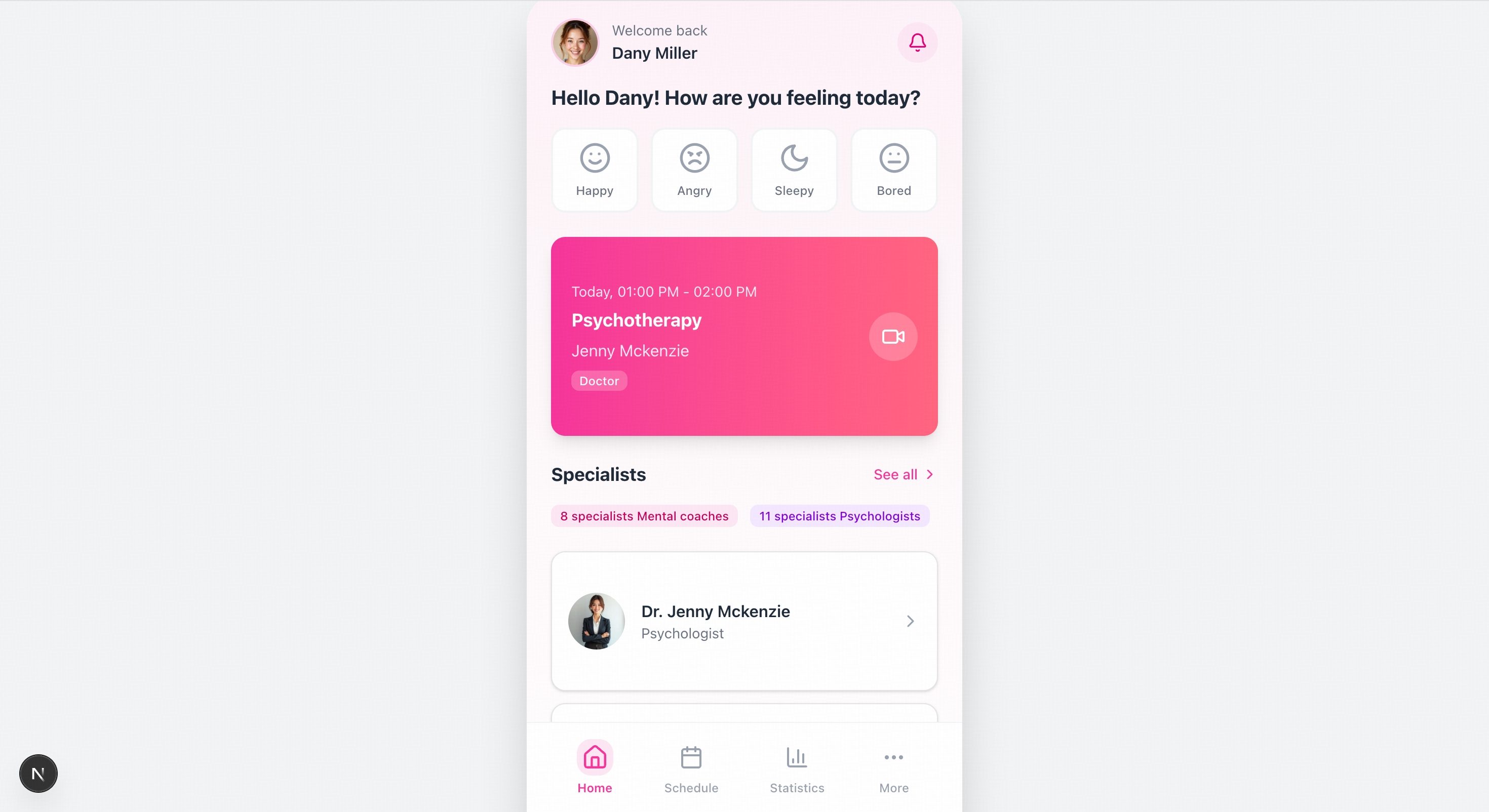
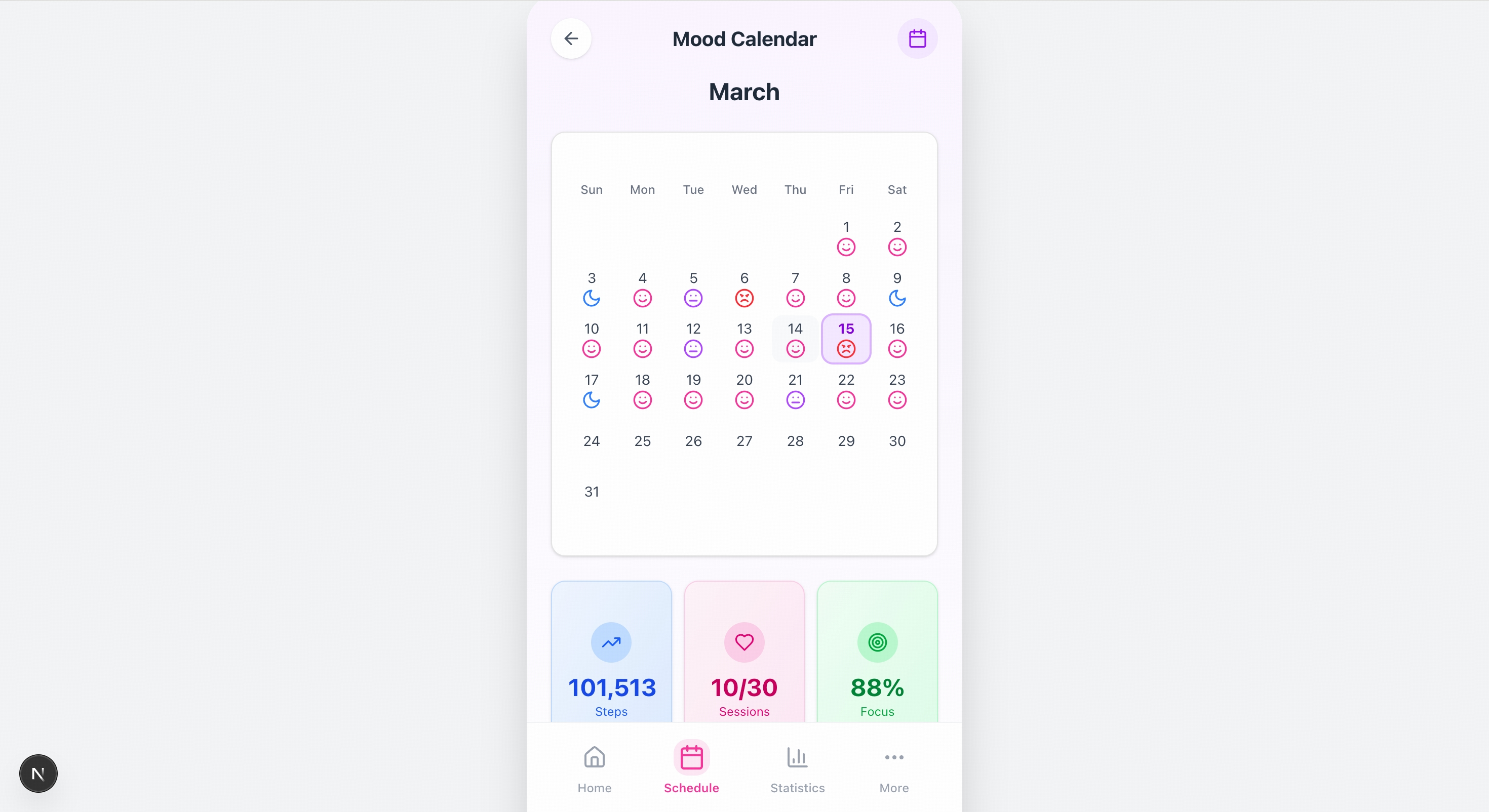
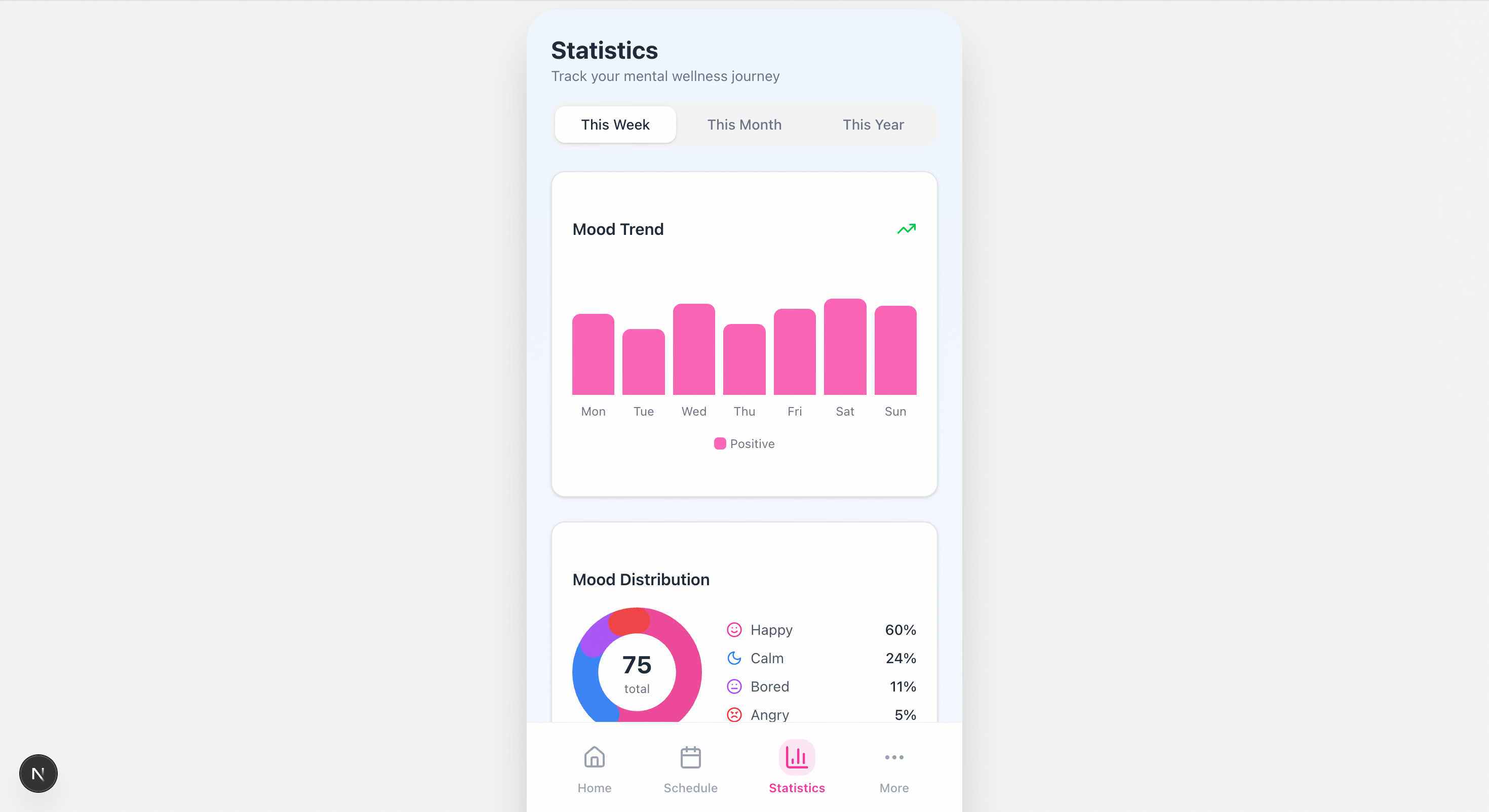
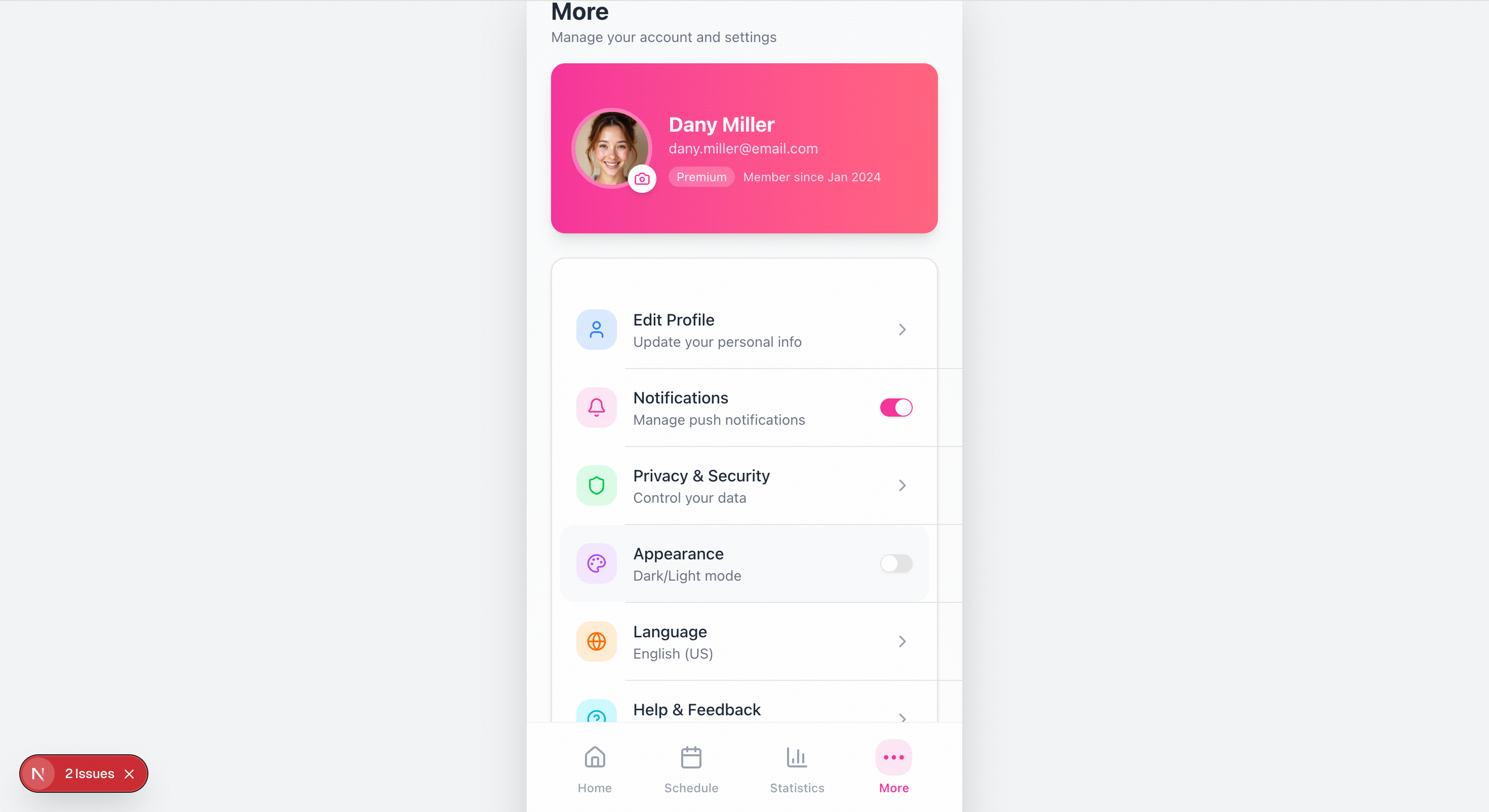



Quick Start
- cURL
- Python
- Java
Basic CallStreaming Call